
간단한 파일 시스템을 어떻게 구현해야할까?
- 파일 시스템은 순수 소프트웨어이다.
- CPU 및 메모리 가상화와 달리, 파일 시스템의 어떤 측면을 개선하기 위해 하드웨어 기능을 추가하지 않는다.
- 데이터 구조
- 파일 시스템은 데이터를 구성하기 위해 어떤 종류의 on-disk 구조를 사용하나?
- 접근 방법
- 파일 시스템은 open(), read(), write() 등과 같은 프로세스가 호출한 함수를 자신의 구조에 어떻게 매핑할까?
전체 구성
vsfs 파일 시스템의 자료 구조에 대해 디스크 상의 전체적인 구성을 개발하자
- 디스크를 block들로 나눈다. (단일 블럭 크기만 사용 가정, 4KB)

Data Region : 사용자 데이터가 있는 디스크 공간, 디스크의 일정 부분을 데이터 영역으로 확보

Meta Data : 각 파일에 대한 정보를 추적
: 파일을 구성하는 데이터 블럭(데이터 영역에 있는 블럭들), 파일의 크기, 소유자와 접근 권한, 접근 및 수정 시간 등을 추적
inode : 메타 데이터를 저장, 디스크에 아이노드 테이블을 위한 공간 예약
inode table : 아이노드 저장을 위한 디스크 공간, 아이노드가 배열 형태로 저장
Allocation structured
: 아이노드 또는 각 블럭이 현재 사용 중인지 또는 비어있는지를 추적해준다. : free list 또는 bitmap 을 사용
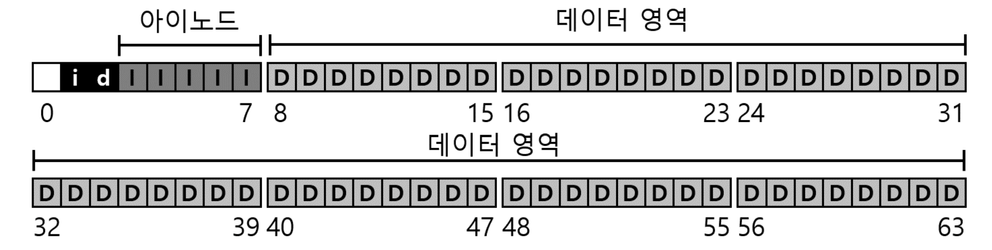
Super Block
이 파일 시스템 전체에 대한 정보를 담는다.
- 파일 시스템에 몇 개의 아이노드와 데이터 블록이 있는지, 아이노드 테이블이 어디서 시작하는지 등의 정보를 포함합
- 파일 시스템을 마운트할 때, 운영 체제는 슈퍼블록을 먼저 읽어 다양한 파라미터를 초기화한 후, 볼륨을 파일 시스템 트리에 연결
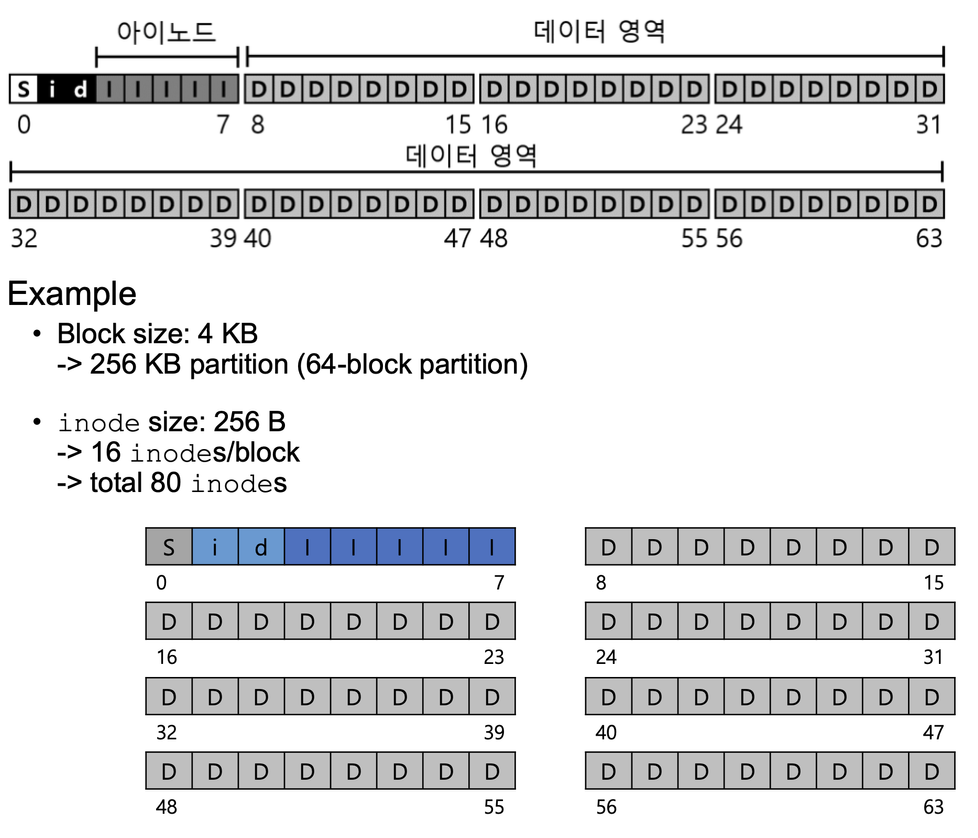
inode
i-number
- 각 아이노드 숫자로 표현
- 아이넘버를 사용하여, 해당 아이노드가 디스크 상에 어디에 있는지를 직접적으로 계산할 수 있다.

[ 예제 : 주소계산하기 ]
- 아이노드 번호 32를 읽기 위해 필요한 계산:
- 아이노드 영역에서의 오프셋 구하기 = $(i-number) * sizeof(inode)$
- inode 크기 : 256byte
- offset = 8KB
- 디스크에서 아이노드 테이블 시작주소 : 12KB
- 전체 주소 = 시작주소 + 오프셋 = 20KB
- 아이노드 영역에서의 오프셋 구하기 = $(i-number) * sizeof(inode)$
- 디스크 섹터 주소 계산:
- 디스크는 바이트 단위로 주소를 지정하지 않고 섹터 단위로 주소를 지정합니다.
- 보통 섹터 크기는 512바이트
- 20KB는 20480바이트입니다.
- 섹터 주소 계산: (20 x 1024) / 512 = 40
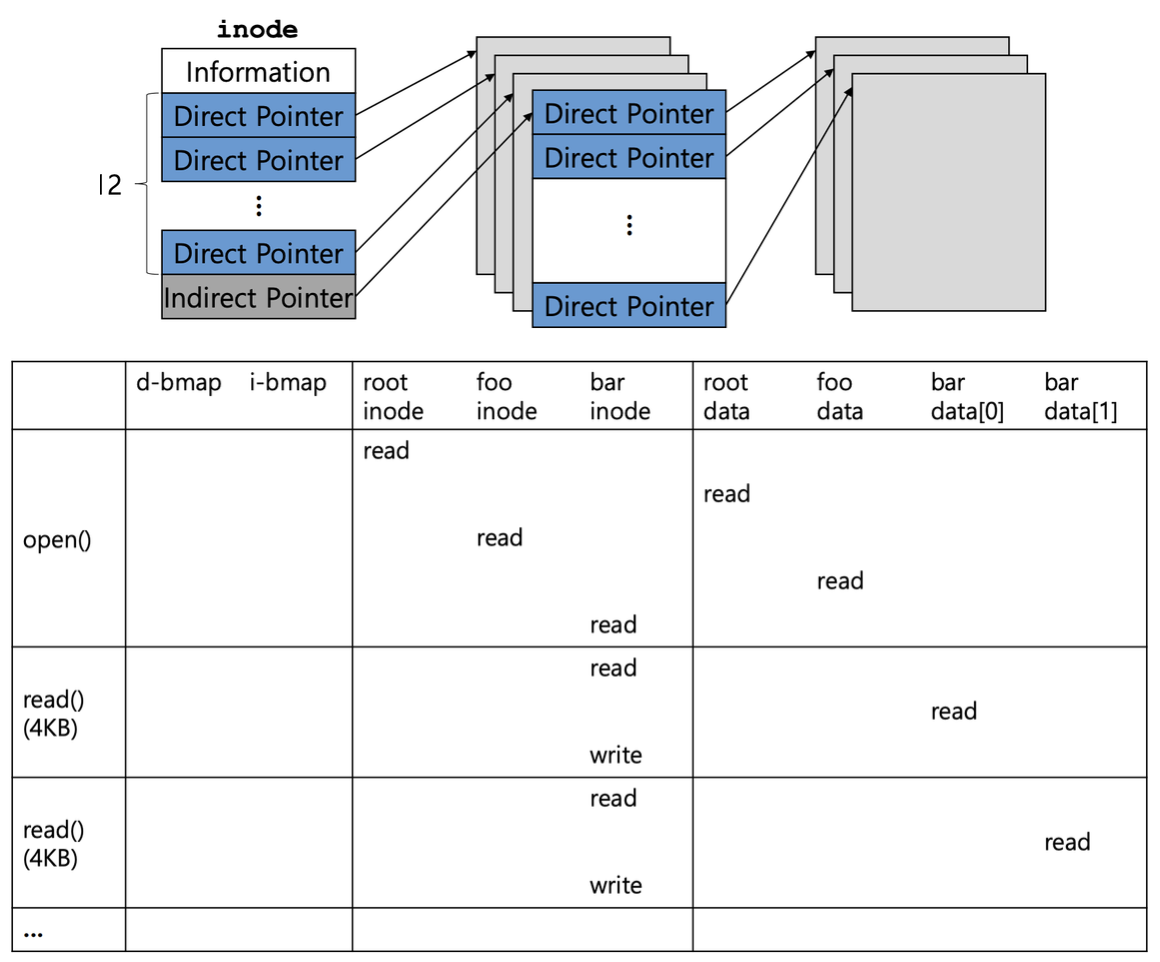
아이노드가 데이터 블록을 참조하는 방법
Multi-Level Index
아이노드는 고정된 수의 직접포인터와 하나의 간접 포인터를 가질 수 있다.
- 직접 포인터 (Direct Pointer): 직접적으로 사용자 데이터가 있는 블록을 가리킨다.
- 간접 포인터 (Indirect Pointer):
- 파일이 충분히 커지면, 간접 블록이 할당된다.
- 이중 간접 포인터 ( Double Indirect Pointer)
- 더 큰 파일을 지원가능
- 간접 블록을 가르키는 포인터를 포함한 블록을 가리킨다.
- 사용자 데이터를 포함한 블록을 가리키는 대신, 더 많은 포인터를 포함한 블록을 가리킨다. 이러한 포인터 각각은 사용자 데이터를 가리킨다.

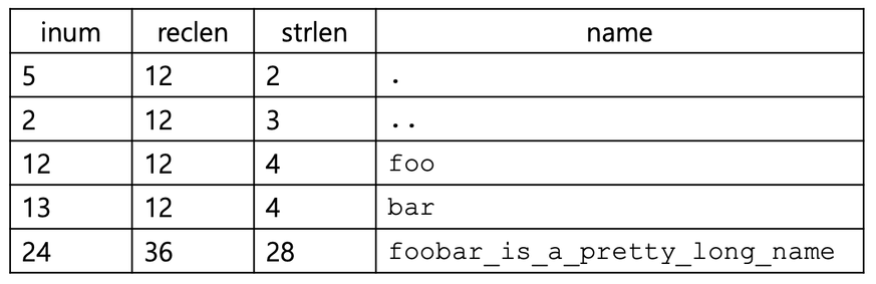
Directory Organization
디렉토리는 특별한 종류의 파일
- 아이노드의 유형 필드는 "일반 파일(regular file)" 대신 "디렉토리(directory)"로 표시
- 데이터 블록에는 (엔트리 이름, i-number) 쌍의 목록이 포함
레코드 길이 (reclen):
이름의 총 바이트 수와 남은 공간을 포함한 전체 바이트 수, 예를 들어, ext4 파일 시스템에서는 4의 배수여야함
문자열 길이 (strlen): 이름의 실제 길이
- 파일을 삭제하면 디렉토리 중간에 빈 공간이 남을 수 있다.예: i-number (inum) -> 0 (예약됨)
- 레코드 길이 (reclen):
- 새 엔트리는 이전의 더 큰 엔트리를 재사용할 수 있으며, 이 경우 여분의 공간이 생길 수 있다.
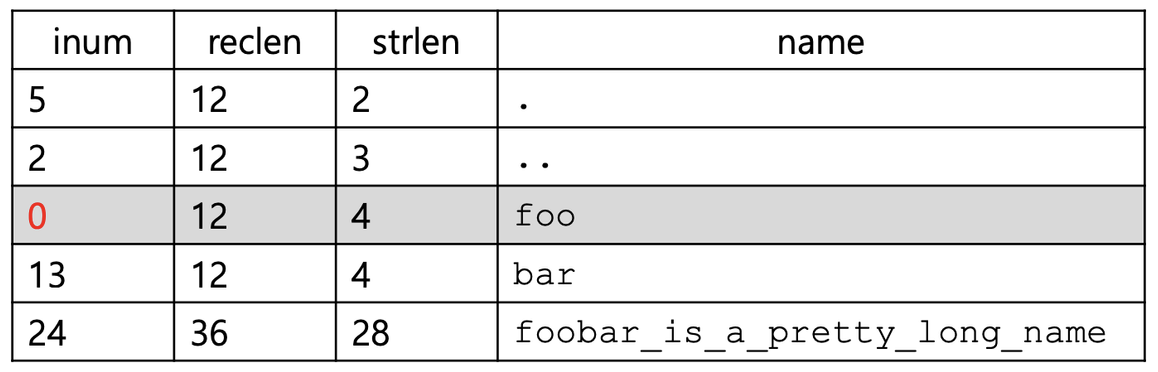
빈공간 관리
- 예: 파일 생성 시( 아이노드 할당해야함 )
- 파일 시스템은 아이노드 비트맵을 탐색하여 비어 있는 아이노드를 찾아 파일에 할당한다. 파일 시스템은 해당 아이노드를 사용중으로 표시하고(1로 표기) 디스크 비트맵도 적절히 갱신
- 데이터 블록도 유사하게 처리된다.
- 일부 파일 시스템은 새로운 파일을 생성할 때 연속된 블록들을 찾아 데이터 블록으로 할당한다
- 이는 파일의 일부가 디스크에서 연속적으로 배치되도록 보장하여 성능을 향상시킨다.

Reading a File from Disk
파일 열기 과정 (open("/foo/bar", O_RDONLY)) 시스템 콜하면 무슨 일이 일어나냐
- 파일 /foo/bar의 아이노드를 찾아서 파일에 대한 기본 정보 획득
- 루트 디렉토리의 아이노드를 읽는다.
- /의 아이노드 번호(i-number)는 보통 2
- 0: 아이노드 없음
- 1: 불량 블록(bad block)
- 디렉토리 엔트리 검색:
- 하나 이상의 디렉토리 데이터 블록을 읽어 foo의 엔트리를 찾는다. (foo의 i-number도 함께 찾음).
- foo의 아이노드를 포함하는 블록을 읽고, foo의 디렉토리 데이터를 읽어 bar의 아이노드 번호를 최종적으로 찾는다.
- bar의 아이노드 읽기:
- bar의 아이노드를 메모리로 읽어들인다.
- 권한 검사: 권한을 확인합니다.
- 파일 디스크립터 할당: 이 프로세스의 프로세스별 열린 파일 테이블에 파일 디스크립터를 할당한다.
- 사용자에게 반환: 파일 디스크립터를 사용자에게 반환한다.
read() 시스템 콜 호출을 통해 파일 읽기
- 파일의 첫 번째 블록을 읽음: ◦ 아이노드를 참조하여 해당 블록의 위치를 찾는다.
- 아이노드 업데이트: 마지막 접근 시간을 새로운 시간으로 업데이트할 수 있다.
- 파일 오프셋 업데이트: ◦ 읽기 작업이 완료되면 파일 오프셋을 업데이트합니다.
close() 시스템 호출
- 파일 디스크립터 해제:
- 파일 디스크립터가 할당 해제
- 디스크 I/O 없음:
- 이 과정에서 디스크 I/O 작업은 발생하지 않는다.
Writing a File to Disk
처음 파일을 여는 과정은 위와 동일하다.
write() 시스템 호출
- 새 파일에 데이터를 쓸 때:
- 각 쓰기 작업은 데이터를 디스크에 쓰기 전에 먼저 파일에 할당할 블록을 결정해야 하며, 이에 따라 디스크의 다른 구조를 업데이트해야 한다.(예: 데이터 비트맵과 아이노드).
- 파일에 쓰기 작업이 논리적으로 생성하는 5개의 I/O 작업:
- 데이터 비트맵을 읽는 작업
- 비트맵을 쓰는 작업
- 아이노드를 읽는 작업
- 아이노드를 쓰는 작업
- 실제 데이터 블록을 쓰는 작업

Caching and Buffering
- 파일 읽기와 쓰기:
- 파일을 읽고 쓰는 작업은 비용이 많이 들며, 많은 I/O가 (느린) 디스크에 발생
- 디렉토리 계층의 각 레벨마다 파일을 열기 위해 최소 두 번의 읽기 작업이 필요하다.
- 해당 디렉토리의 아이노드를 읽는 작업
- 아이노드 기반으로 디렉토리 데이터를 읽는 최소 한 번의 작업.
- 페이지 캐시 (Page Cache):
- 첫 번째 파일 열기는 디렉토리 아이노드와 데이터를 읽기 위해 많은 I/O 트래픽을 발생시킬 수 있다.
- 동일한 파일 또는 같은 디렉토리 내의 파일을 이후에 여는 작업은 대부분 캐시에서 히트하게 된다.
쓰기 버퍼링 (Write Buffering)
- 쓰기 지연:
- 파일 시스템은 쓰기 작업을 지연시켜 여러 업데이트를 하나의 작은 I/O 세트로 묶을 수 있다.
- 이를 통해 여러 쓰기 작업을 일괄 처리하여 효율성을 높일 수 있다.
- 후속 I/O 작업 스케줄링:
- 지연된 쓰기 작업을 모아서 나중에 실행될 I/O 작업을 스케줄링할 수 있다.
- 이를 통해 I/O 작업을 최적화하고 디스크 접근 시간을 줄일 수 있다.
- 쓰기 작업의 회피:
- 쓰기 작업을 지연함으로써, 일부 쓰기 작업은 완전히 피할 수 있다.
- 예를 들어, 동일한 파일에 여러 번의 쓰기 작업이 연속으로 발생할 경우, 마지막 쓰기 작업만 실제로 디스크에 기록될 수 있다.
[출처]
https://github.com/remzi-arpacidusseau/ostep-translations/blob/master/korean/README.md
ostep-translations/korean/README.md at master · remzi-arpacidusseau/ostep-translations
Various translations of OSTEP can be found here. Help the cause and contribute! - remzi-arpacidusseau/ostep-translations
github.com
해당 책을 기반으로 정리하였습니다.
'Computer Science' 카테고리의 다른 글
| 운영체제를 알아보자 (2) | 2025.03.31 |
|---|---|
| [OSTEP 운영체제 정리] - Log-Structured File System (0) | 2024.06.24 |
| [OSTEP 운영체제 정리] - File and Directories (0) | 2024.06.24 |
| [OSTEP 운영체제 정리] - IO and HDD (0) | 2024.06.24 |
| [OSTEP 운영체제 정리] - Concurrency Problem (0) | 2024.06.24 |